激光芯片为AI数据中心带来多路复用技术
随着AI数据中心的带宽和功耗需求推动从电气网络向光学扩展网络的转型,协同封装光学器件中一直缺少一个关键组件:激光器本身。现在这种情况已经改变。上个月,Tower半导体公司和Scintil光子公司宣布生产出世界首款用于AI基础设施的单芯片DWDM光引擎。
DWDM即密集波分复用,能够在单根光纤中传输多个光信号,在连接数十个GPU的同时大幅降低功耗和延迟。
Scintil光子公司CEO Matt Crowley表示,光学多路复用的概念并不新颖。实际上,这项技术与互联网同样历史悠久。在20世纪90年代,电信公司在街道下铺设了大量光纤,假设每根光纤最终只使用一个波长。当电信行业意识到通过多路复用技术可以在单根光纤中传输数十个波长时,这彻底革新了整个行业。
DWDM技术尚未在专门处理AI应用的数据中心中部署的原因在于,该技术在成本和需求方面还不具备可扩展性。Crowley说:"AI数据中心内传输的数据相当于大规模扩展一台超级计算机。"特别是在扩展网络中面临挑战,即直接连接机架或集群内的加速器(XPU,扩展处理单元),这与连接数据中心内不同集群的横向扩展网络不同。优化数十个GPU和内存使其作为单一实体运行需要无缝带宽和极低延迟。
为了增加带宽、降低延迟并提高AI数据中心的能效,网络工程师逐渐用光学链路替换铜缆链路。可插拔收发器通过集成在单芯片上的分立光学组件将电信号转换为光信号,反之亦然:这就是协同封装光学器件(CPO)。
Crowley说:"大型芯片公司制造的所有产品都涉及将光学芯片绑定到其GPU上。"CPO成为处理器的输入/输出芯片。但由于缺乏将激光器本身集成到相同硅工艺流程中的可扩展方法,因此无法在一个芯片上为每根光纤提供多个波长。Scintil和Tower将在2026年3月17日至19日在洛杉矶举行的OFC 2026会议上讨论其制造路线图和细节。
创新技术
Scintil的"SHIP"(Scintil异质集成光子学)技术将激光器、光电二极管、调制器和其他组件集成到批量生产的硅晶圆上。Crowley说:"这是我们版本的CMOS",但采用了一些技巧来解决将光学增益材料绑定到硅上的固有挑战。
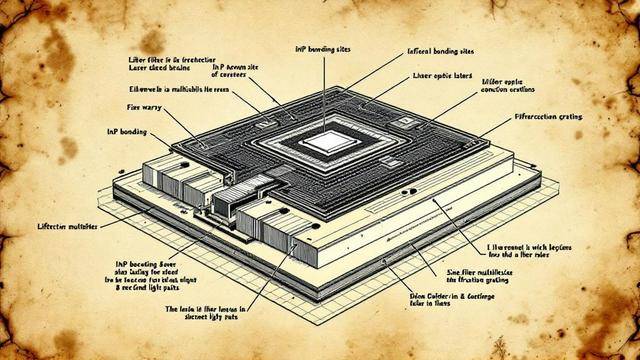
该工艺从Tower半导体公司的标准300毫米硅光子晶圆开始,包含无源光学组件。接下来,将晶圆翻转以暴露其埋氧层。将未图案化的InP/III-V半导体芯片的微小方块精确绑定到每个激光器位置所需的层上,最大限度地减少昂贵半导体材料的使用量。最后,光刻工具蚀刻衍射光栅形成八个分布反馈激光器。
Crowley说:"我们不是在重新发明激光器。"相反,先进的光刻工具比传统制造在硅晶圆上能够提供更精确的间距和波长稳定性。
最终产品是"LEAF Light"光子集成电路,这是一个集成两组八个分布反馈阵列的芯片。每个光纤端口提供8个或16个波长,通道间距为100或200千兆赫,确保无重叠或模式跳跃。第二个ASIC芯片承载控制和监控激光阵列的所有电子器件。
性能优势
Crowley说:"这是在CPO芯片上构建激光器。"英伟达和博通已经部署了每根光纤单波长的CPO,证明其在横向扩展网络中的可行性。"我们正在实现下一代CPO的扩展。"
通过单根光纤传输多个波长使行业朝着理想的"慢而宽"架构发展。例如,LEAF Light芯片不是在单个信道或波长上传输400 Gb/s,而是在8个信道上分布50 Gb/s,大大增加每根光纤的数据容量和整体功耗效率。该设计能够在单根光纤中实现高达1.6太比特每秒的数据速度,英伟达最近的路线图表明,未来的DWDM互连最终可能实现每比特低于1皮焦耳的操作。
据Crowley说,最重要的好处可能是延迟方面。他说:"我需要保持GPU之间的低延迟。"如果任何单个处理器的运行速度超过整个网络,GPU总是在等待数据位进行处理——这个问题在有数十或数百个GPU的扩展网络中被放大。高带宽信道上的前向处理和纠错增加了延迟不良的几率。Crowley说:"GPU的利用率直线下降。"使用低带宽DWDM连接多个GPU可以使利用率翻倍。
Scintil和Tower将在2026年底向客户提供数万台设备,并计划明年将产量提高一个数量级。到2028年,当客户打算在扩展网络中部署DWDM时,供应链将为他们做好准备。Crowley说:"我们对它可能开启的可能性感到兴奋。"
Q&A
Q1:DWDM技术是什么?它在AI数据中心中有什么作用?
A:DWDM即密集波分复用,能够在单根光纤中传输多个光信号,在连接数十个GPU的同时大幅降低功耗和延迟。它通过在单根光纤中传输多个波长来增加数据容量和整体功耗效率。
Q2:Scintil的SHIP技术有什么特别之处?
A:SHIP技术将激光器、光电二极管、调制器和其他组件集成到批量生产的硅晶圆上。它采用先进的光刻工具,比传统制造在硅晶圆上能够提供更精确的间距和波长稳定性。
Q3:使用DWDM技术在GPU连接上有什么优势?
A:最重要的优势是降低延迟。如果单个处理器运行速度超过整个网络,GPU会一直等待数据处理,导致利用率下降。使用低带宽DWDM连接多个GPU可以使利用率翻倍,大大提升整体性能。
下一篇:存储芯片股领涨