英伟达 GB10 SoC 架构解析|Hot Chips 2025
芝能智芯出品
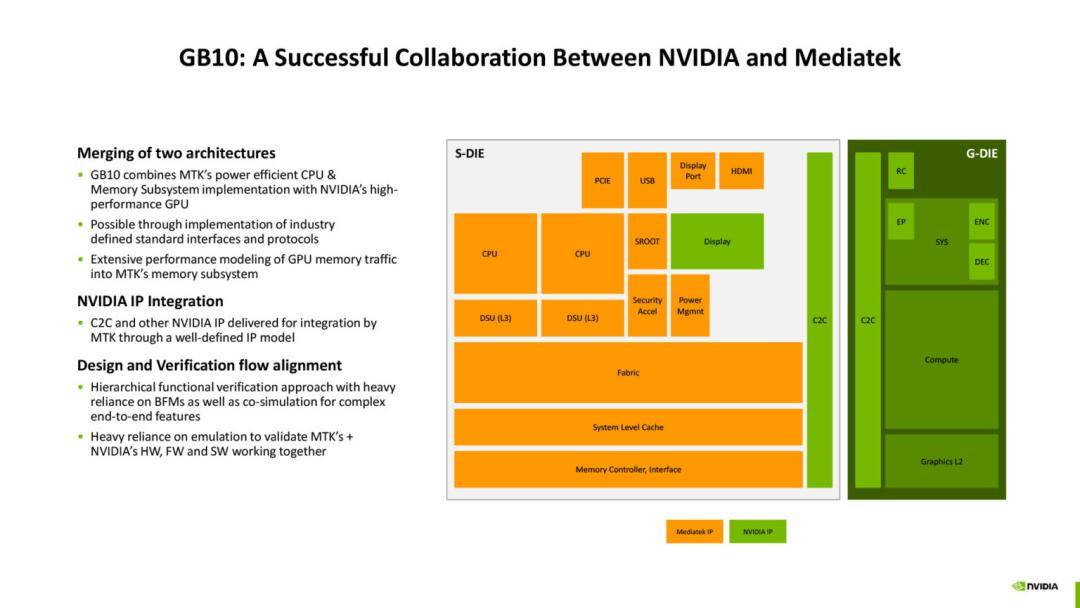
在 2025 年 Hot Chips 大会上,英伟达正式对外详细介绍了其最新的 GB10 SoC 架构,这是Blackwell 架构 GPU 的一次“缩微”应用,更通过与联发科的合作,将 20 个 Arm v9.2 CPU 内核与高性能 GPU 结合在单一 2.5D 封装之中,形成了 Grace Blackwell 的小型化集成版本。
GB10 的推出并不是单纯的性能堆叠,而是面向高性能工作站、桌面级 AI 开发和轻量化数据中心的整体解决方案。
在统一内存架构、CPU/GPU 缓存一致性、C2C 链接、低功耗设计和易用性等方面做出了大量优化,从而使得 DGX Spark 小型工作站能够在有限功耗和体积下,承担起此前必须依赖大型数据中心系统的部分任务。
GB10 的意义为 AI 开发的生态闭环提供了一个“网关”级产品,使本地开发与云端部署能够顺畅衔接。

Part 1
GB10 SoC
的架构特征与设计逻辑
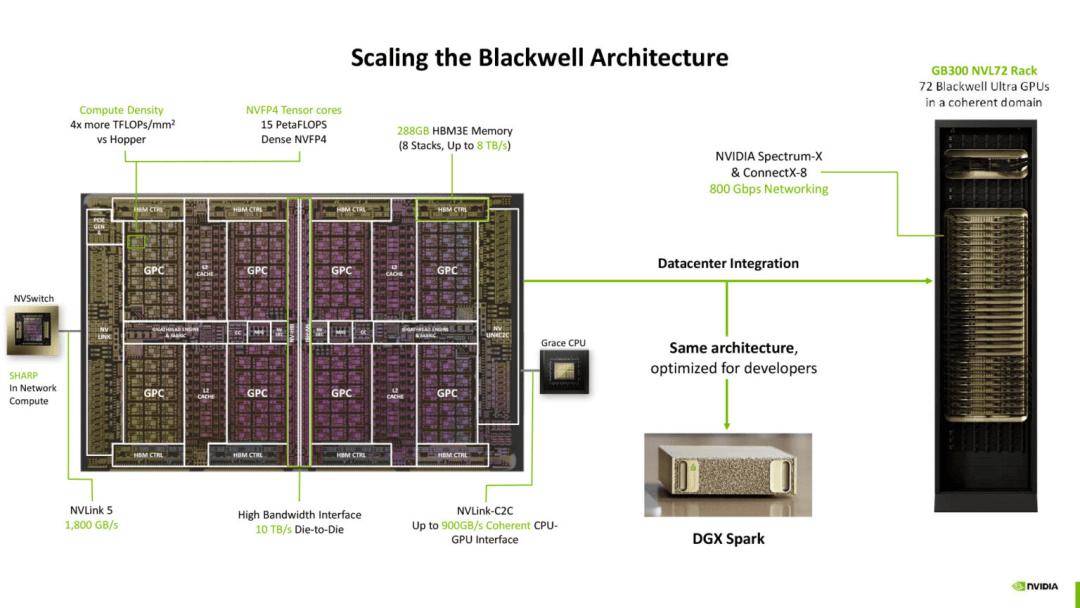
在本次 Hot Chips 的分享中,英伟达强调 GB10 的定位并不是传统意义上的数据中心芯片,而是面向 DGX Spark 这一轻量化工作站所打造的 SoC 方案。

它整合了 CPU 与 GPU 两个核心计算单元,采用台积电 3nm 工艺制造,并通过 2.5D 中介层进行封装。
这一设计首先保证了整体功耗维持在 140 瓦的可控范围内,使得产品可以依靠标准壁式电源插座供电,而无需服务器机柜的复杂配电环境,这对于中小型研究团队、开发人员和实验室场景具有现实意义。
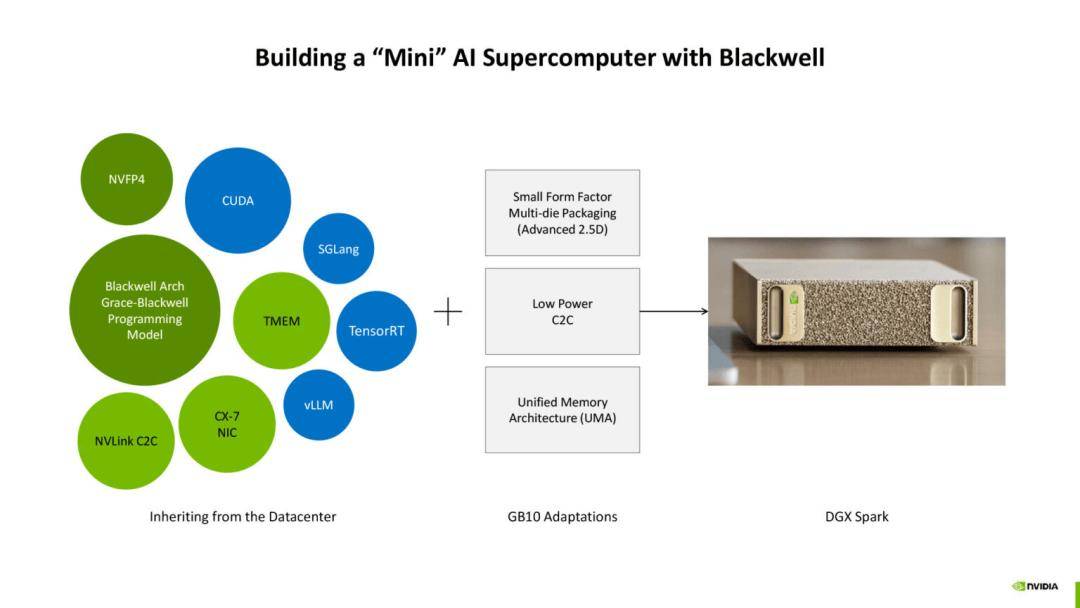
CPU 部分由联发科提供,基于 Arm v9.2 架构,共有 20 个内核,分成两个集群,每个集群包含 10 个核心,并配备 16MB 共享的 L3 缓存,总计 32MB,同时每个核心仍保留独立的 L2 缓存。

使得 CPU 在处理大规模并行任务与中小规模串行任务时能够灵活切换,既保证了延迟控制,又提升了多线程吞吐能力。
更关键的是,内存子系统采用统一的 LPDDR5X-9400 架构,总线宽度为 256 位,提供约 301GB/s 的带宽,支持最高 128GB 的容量。
CPU 与 GPU 在这一统一内存体系下共享数据,避免了频繁的内存复制和同步开销,这对于 AI 模型训练与推理中参数频繁调用的场景具有决定性意义。

GPU 部分则是 Blackwell 架构的一个缩小化版本。虽然规模缩小,但其核心特性完整保留,特别是 FP4 运算支持,使得在超低精度推理场景中,能够实现高达 1000 TOPS 的计算性能,而 FP32 峰值性能为 31 TFLOPS。
在硬件层面,GPU 内部拥有一个 24MB 的二级缓存,并与 CPU 保持一致性,这通过地址转换服务(ATS)和硬件管理实现,极大降低了跨芯片通信的延迟。
这种 CPU/GPU 缓存一致性是 GB10 架构的亮点之一,它让开发者无需在软件层面管理复杂的同步逻辑,进一步简化了编程和工作流。

C2C(Chip-to-Chip)链路在 GB10 中也发挥了关键作用,它提供约 600GB/s 的带宽,实现低延迟共享。相比传统 PCIe 的通信方式,这一专用链路能够更好地支撑 CPU 与 GPU 的数据交换。
再加上 ConnectX-7 网卡的集成,DGX Spark 可以通过 PCIe 5.0 x8 通道与另一台 Spark 配对,形成双机互联,共同处理更大规模的模型。
虽然受限于带宽,网卡的两个 200Gbps 接口无法同时满速运行,但对于分布式小规模任务而言,已经具备实用价值。

GB10 SoC 的设计逻辑在于平衡体积、功耗与性能。它并不追求与完整的 DGX 系统相同的峰值表现,而是通过合理的 CPU/GPU 组合、统一内存架构和缓存一致性,将开发者最常用的任务在一台桌面级设备上顺畅运行,为大规模训练提供前置的实验环境。
Part 2
DGX Spark
的应用价值与产业意义
DGX Spark 的推出,不仅仅是硬件层面的创新,更是英伟达生态战略的延伸。
在实际应用中,Spark 工作站配备高达 128GB 的统一系统内存和最高 4TB 的 SSD 存储,可以支持多达 700 亿参数的模型微调。
这一能力直接覆盖了主流大模型的实验需求,使开发者可以在本地完成从数据处理、模型训练到验证的完整流程,而无需一开始就依赖昂贵的数据中心资源。
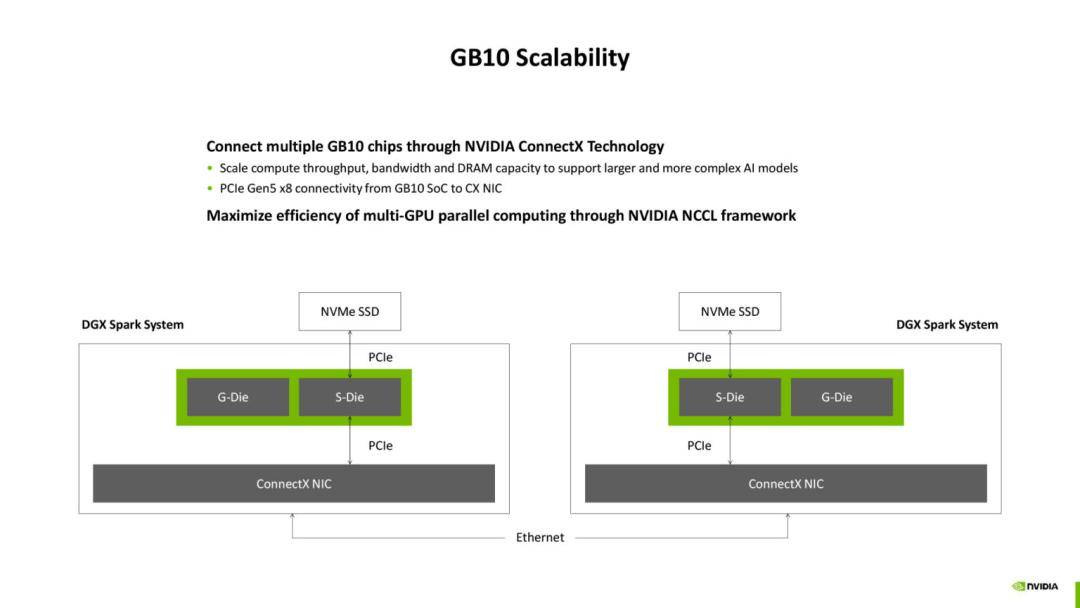
在连接性方面,Spark 系统自带 ConnectX-7 网卡,允许双机互联。
尽管性能不及 DGX SuperPOD 这样的高端集群,但对于中小团队来说,双机 Spark 的组合已经能够胜任不少研究和商用开发任务。这种模式降低了 AI 开发的入门门槛,让更多用户能够以较低的成本进入大模型应用的实验阶段。
英伟达并不掩饰 Spark 的“网关”定位。其设计初衷是让用户在本地进行开发与验证,然后将成熟的模型迁移至 DGX Cloud 或更大规模的 DGX 系统进行部署。这种从桌面到云端的迁移路径,体现了英伟达对自身生态的深度整合。
Spark 成为一个衔接点,使得个人开发者与企业用户能够在同一个 CUDA 软件栈下平滑过渡,不会因硬件环境的差异而改变开发逻辑。
GB10 SoC 的出现也说明了英伟达在 CPU/GPU 协同上的进一步开放态度。
与联发科的合作,标志着英伟达在 CPU 领域不再坚持自研,而是通过生态合作快速补齐短板。这种跨企业的深度绑定,未来可能影响到高性能计算和消费级产品的更多领域。
例如,传闻中的 N1/N1x SoC 就有可能基于 GB10 的设计理念下沉到消费级笔记本,从而实现 GPU 技术在更广泛市场的普及。
GB10 与 Spark 的推出,也是在应对 AI 芯片市场快速多元化的压力。随着 AMD、Intel 以及初创企业纷纷推出面向 AI 的 SoC 方案,英伟达需要在高端数据中心之外,找到新的市场突破口。
Spark 和 GB10 提供的“轻量级 AI 超算”体验,正是这种市场战略的体现。它不仅巩固了英伟达在 AI 开发者社区的地位,也进一步扩大了 CUDA 生态的势能。
DGX Spark 的应用价值体现在三个层面:
◎一是为开发者提供了低门槛、高性能的本地开发环境;
◎二是构建了从桌面到云端的生态闭环;
◎三是通过跨界合作和技术下沉,拓展了英伟达的市场版图,使得 GB10 SoC 不仅仅是一次硬件创新,更是一种产业布局。
小结
在 Hot Chips 2025 上,英伟达用 GB10 SoC 展示了其在 CPU/GPU 协同、统一内存架构和低功耗高性能设计上的新思路。DGX Spark 作为其落地载体,既是技术成果的呈现,也是生态战略的实践。
它通过“缩小版 Blackwell + Arm CPU”的组合,为中小型团队提供了可及的 AI 开发平台,同时与云端 DGX 系统无缝衔接,形成完整的开发与部署通路。
GB10 SoC 为桌面级 AI 开发设定了新的性能基准,也可能成为未来消费级 SoC 的蓝本。而 Spark 工作站的推广,则有望推动 AI 开发生态的进一步普及,让更多的用户群体能够直接参与到大模型的实验与应用之中。